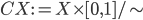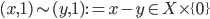Recently I had the good fortune to both attend #TMC13 and share my very own personal favorite lesson during, appropriately, one of the "My Favorite" sessions. And now I'll share it with you.
I was getting ready to start a unit on conic sections with my Advanced Algebra kids. I was planning to start, as I assume many of you do, with circles. I imagined it going something like this, Lusto's 10 Steps to Circle Mastery:
- Get somebody, anybody in the room, to spout the definition of a circle , hopefully including a phrase such as, "the set of all points a fixed distance from a given point..."
- Talk about this distance business. Do we know something about distance? How do we measure it?
- The distance formula.
- Why the distance formula is fugly. Remember the Pythagorean Theorem? Of course you do. It's awesome.
- In the plane:

- In the Cartesian plane, centered at the origin:

- This distance, d, has a special name in circles, right? Right:

- Appeal to function families and translations by <h, k>.

- Boom.
Based on my hopes for Step 1, and based on my need for like five uninterrupted minutes to take attendance, find my coffee mug, &c., I hastily scribbled an extremely lazy and unimaginative warm-up discussion question on the whiteboard. Four simple words that led to some surprising and amazing mathematical conversation.
What is a circle?
That's it. My favorite lesson. The whole thing. And here's how it went.
I was walking around looking at/listening to all the different definitions the groups had come up with. And they were nuts. There were dubious claims about unquantifiable symmetry, sketchy sketches with line segments of indeterminate provenance, rampant appeals to a mysterious property known as roundness. Most of the arguments were logically circular but, alas, mathematically not. The word curvy appeared more than once. It was a glorious disaster of handwaving and frustration. I knew, deep in my reptilian brain, that this is what's known in the business as a "teachable moment."

Nailed it.
At this point I was basically just walking around being a jerk. I was drawing all kinds of crazy figures that minimally conformed to what they were telling me a circle was, and getting lots of laughs in the process. And then I had the thought, even deeper in my reptilian brain, that transformed the whole experience from an interesting activity into a bonafide lesson: Why the hell am I the one doing this?
So here's what the lesson eventually became, Lusto's 6 Instructions to Humans on the Brink of Amazing Mathematical Discussion:
- In your groups, answer the question, "What is a circle?"
- Absolutely no book-looking or Googling. If all goes well, you will be frustrated. Your peers will frustrate you. I will frustrate you. Don't rob anybody else of this beautiful struggle. If your definition includes the word locus, you are automatically disqualified from further participation.
- Each group will have one representative present your definition to the class. No clarification. No on-the-fly editing. No examples. No pantomime. Your definition will include, and be limited to, English words in some kind of semantically meaningful order. Introduce variables at your own risk.
- If you're going to refer to some other mathematical object (and I suspect you will), make sure it's not an object whose definition requires the concept of circle in the first place. (Ancillary benefit: you will be one of the approximately .01% of the population who learns what "begging the question" actually means.)
- Once a group presents a definition, here is your new job: construct a figure that meets the given definition precisely, but is not a circle. Pick nits. You are a counterexample machine. A bonus of my undying respect for the most ridiculous non-circle of the day.
- When you find a counterexample, make a note of the loophole you exploited. What is non-circley about your figure?
After giving the instructions, I could pretty much just sit back for a while and watch things get awesome. If there's one thing that's easy to do, it's get teenagers to argue with each other. Granted, it's a little harder to get them to argue about math, but not much. (They're basically ready to fight at all times; the MacGuffin is largely unimportant.) So that's one thing that makes this lesson my favorite. Another thing is that we ended up with a pretty bullet-proof circle definition by the end of the exercise. When you spend a whole lot of time crawling through loopholes in the hopes of beating up on your peers, you find an awful lot of loopholes to close. Talk about a fantastic mathematical habit of mind. Yet another thing, and maybe the coolest, is that it led to some of the best questions/observations my kids ever came up with. Here is a brief, paraphrased sampling, with my annotations as to why they're so great:
- Wait, if the circle is just the points on the edge, then how can a circle have area? There's nothing that gets kids thinking precisely about mathematical language faster than the realization that every teacher in the world is using it incorrectly. We should really be saying, the area of the region bounded by a circle, or the area of the circle's interior... I had never thought twice about that, but now I sure as hell do.
- What does it mean to be "inside" a circle? Similar to the above, but even more amazing. The fact that a circle divides the plane into two disjoint regions is a completely nontrivial result. It's basically a statement of the Jordan Curve Theorem, which was proved pretty recently in the history of mathematics.
- If a radius is a distance, then a "circle" depends on how you measure distance. This one is on my Holy Shit List. We had spent like a half hour one day talking about the Taxicab Plane, just because I thought it was cool and made the distance formula seem mildly less boring. But somebody pointed out that circles would look totally different if we measured distances that way. And yes! They would! At that point, I felt like I should probably just retire.
The final reason this lesson is my favorite is probably also the reason that you should care. There's nothing particularly special about the word circle. You can take the sentence, What is a [widget]? and pick just about any mathematical widget that kids have some nascent intuition about. Give it a shot. Maybe it won't be your favorite, but it'll be pretty great.