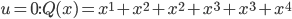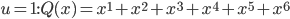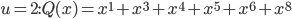What is luck? Is luck? And, if you vote yea, is a belief in luck an obstacle to understanding probability?
This question came up on Twitter a couple of nights ago when Christopher Danielson and Michael Pershan were discussing Daniel Kahneman's recent book, Thinking, Fast and Slow. Specifically, they were talking about the fact that Kahneman doesn't shy away from using the word luck when discussing probabilistic events. This, of course, is the kind of thing that makes mathematically fastidious people cringe. And Danielson and Pershan are nothing if not mathematically fastidious. Spend like five minutes with their blogs. So Danielson twittered this string of twitterings:

According to Danielson, luck a "perceived bias in a random event." And, according to his interpretation of Kahneman, luck is composed of "happy outcomes that can be explained by probability." Let me see if I can define luck for myself, and then examine its consequences.
What is luck?
I think, at its heart, luck is about whether we perceive the universe to be treating us fairly. When someone is kind to us, we feel happy, but we can attribute our happiness to another's kindness. When someone is mean, we feel sad, but we can attribute our sadness to another's meanness. When we are made to feel either happy or sad by random events, however, there is no tangible other for us to thank or blame, and so we've developed this idea of being either lucky or unlucky as a substitute emotion.
But happy/sad and lucky/unlucky are relative feelings, and so there must be some sort of zero mark where we just feel...nothing. Neutral. With people, this might be tricky. Certainly it's subjective. Really, my zero mark with people is based on what I expect of them. If a stranger walks through a door in front of me without looking back, that's roughly what I expect. And, when that happens, I do almost no emoting whatsoever. If, however, he holds the door for me, this stranger has exceeded my expectations, which makes me feel happy at this minor redemptive act. If he sees me walking in behind him and slams the door in my face, he has fallen short of my expectations, which makes me sad and angry about him being an asshole.
And, in this regard, I think that feeling lucky is actually a much more rational response than being happy/sad at people, because with random events at least I can concretely define my expectation. I have mathematical tools to tell me, with comforting accuracy, whether I should be disappointed with my lot in life; there is no need to rely on messy inductive inferences about human behavior. So I feel lucky when I am exceeding mathematical expectations, unlucky when I'm falling short, and neutral when my experience roughly coincides with the expected value. Furthermore, the degree of luck I feel is a function of how far I am above or below my expectation. The more anomalous my current situation, the luckier/unluckier I perceive myself to be.
Let's look at a couple examples of my own personal luck.
- I have been struck by lightning zero times. Since my expected number of lightning strikes is slightly more than zero, I'm doing better than I ought to be, on average. I am lucky. Then again, my expected number of strikes is very, very slightly more than zero, so I'm not doing better by a whole lot. So yeah, I'm lucky in the lightning department, but I don't get particularly excited about it because my experience and expectation are very closely aligned.
- I have both my legs. Since the expected number of legs in America is slightly less than two, I'm crushing it, appendage-wise. Again, though, I'm extremely close to the expected value, so my luck is modest. But, I am also a former Marine who spent seven months in Iraq during a period when Iraq was the explosion capital of the world. My expected number of legs, conditioned on being a war veteran, is farther from two than the average U.S. citizen, so I am mathematically justified in feeling luckier at leg-having than most leg-having people in this country.
Which brings us back to this business of luck being a "perceived bias in a random event." I'm not convinced. In fact, I'm absolutely sure I can be lucky in a game I know to be unbiased (within reasonable physical limits). Let's play a very simple fair game: we'll flip a coin. I'll be heads, you'll be tails, and the loser of each flip pays the winner a dollar. Let's say that, ten flips deep, I've won seven of them. I'm up $4.00. Of course, my expected profit after ten flips is $0, so I'm lucky. And you, of course, are down $4.00, so you're unlucky. Neither of us perceives the game to be biased, and we both understand that seven heads in ten flips is not particularly strange (it happens about 12% of the time), and yet I'm currently on the favorable side of randomness, and you are not. That's not a perception; that's a fact. And bias has nothing to do with it, not even an imaginary one.
Now, in the long run, our distribution of heads and tails will converge toward its theoretical shape, and we will come out of an extremely long and boring game with the same amount of money as when we started. In the long run, whether we're talking about lightning strikes or lost limbs or tosses of a coin, nobody is lucky. Of course, in the long run---as Keynes famously pointed out---we'll be dead. And therein, really, is why luck creeps into our lives. At any point, in any category, we have had only a finite number of trials, which means that our experiences are very likely to differ from expectation, for good or ill. In fact, in many cases, it would be incredibly unlikely for any of us to be neither lucky nor unlucky. That would be almost miraculous. So...
Is luck?
As in, does it really exist, or is it just a perceptual trick? Do I only perceive myself to be lucky, as I said above, or am I truly? I submit that it's very real, provided that we define it roughly as I just have. It's even measurable. It doesn't have to be willful or anthropomorphic, just a deviation from expectation. That shouldn't be especially mathematically controversial. I think the reason mathy people cringe around the idea of luck is because it's so often used as an explanation, which is where everything starts to get a little shaky. Because that's not a mathematical question. It's a philosophical or---depending on your personal bent---a religious one.
If you like poker, you'd have a tough time finding a more entertaining read than Andy Bellin's book, Poker Nation. The third chapter is called "Probability, Statistics, and Religion," which includes some gems like, "...if you engage in games of chance long enough, the experience is bound to affect the way you see God." It also includes a few stories about the author's friend, Dave Enteles, about whom Bellin says, "Anecdotes and statistics cannot do justice to the level of awfulness with which he conducts his play." After (at the time) ten years of playing, the man still kept a cheat sheet next to him at the table with the hand rankings on them. But all that didn't stop Dave from being the leading money winner at Bellin's weekly game during the entire 1999 calendar year. "The only word to describe him at a card table during that time is lucky," says Bellin, "and I don't believe in luck."
But there's no choice, right, but to believe? I mean, it happened. Dave's expectation at the poker table, especially at a table full of semi-professional and otherwise extremely serious and skillful players, is certainly negative. Yet he not only found himself in the black, he won more than anybody else! That's lucky. Very lucky. And that's also the absolute limit of our mathematical interest in the matter. We can describe Dave's luck, but we cannot explain it. That way lies madness.
There are 2,598,960 distinct poker hands possible. There are 3,744 ways to make a full house (three-of-a-kind plus a pair). So, if you play 2,598,960 hands, your expected number of full houses during that period is 3,744. Of course, after 2.6 million hands, the probability of being dealt precisely 3,744 full houses isn't particularly large. Most people will have more and be lucky, or less and be unlucky. That's inescapable. Now, why you fall on one side and not the other is something you have to reconcile with your favorite Higher Power.
Bellin's final thoughts on luck:
I know in my heart that if Dave Enteles plays 2,598,960 hands of poker in his life, he's going to get way more than his fair share of 3,744 full houses. Do you want to know why? Well, so do I.
And, really, that's the question everybody who's ever considered his/her luck struggles to answer. No one has any earthly reason to believe she will win the lottery next week. But someone will. Even with a negative expectation, someone will come out way, way ahead. And because of that, we can safely conclude that that person has just been astronomically lucky. But why Peggy McPherson? Why not Reggie Ford? Why not me? Thereon we must remain silent.
Is a belief in luck an obstacle to understanding probability?
I don't see why it should be. At least not if we're careful. If you believe that you are lucky in the sense of "immune to the reality of randomness and probabilistic events," then that's certainly not good. If you believe that you are lucky in the sense of "one of the many people on the favorably anomalous side of a distribution," then I don't think there is any harm in it. In fact, acknowledging that random variables based on empirical measurements do not often converge toward their theoretical limits particularly rapidly is an important feature of very many random variables. In other words, many random variables are structured in such a way as to admit luck. That's worth knowing and thinking about.
Every day in Vegas, somebody walks up to a blackjack table with an anomalous number of face cards left in the shoe and makes a killing. There is no mystery in it. If you're willing to work with a bunch of people, spend hours and hours practicing keeping track of dozens of cards at a time, and hide from casino security, you can even do it with great regularity. There are how-to books. You could calculate the exact likelihood of any particular permutation of cards in the shoe. I understand the probabilistic underpinnings of the game pretty well. I can play flawless Basic Strategy without too much effort. I know more about probability than most people in the world. And yet, if I happen to sit at a table with a lot more face cards than there ought to be, I can't help but feel fortunate at this happy accident. For some reason, or for no reason, I am in a good position rather than a bad one; I am here at a great table instead of the guy two cars behind me on the Atlantic City Expressway. That's inexplicable.
And that's luck.